

Семантическое ядро (СЯ) сайта – ключевой элемент при его продвижении. Более того, от качества СЯ во многом зависит и эффективность работы PPC-кампаний (Pay-per-Click – показ рекламных объявлений в сетях Google AdWords или Яндекс.Директ). Поэтому составление семантического ядра и кластеризация запросов – первое, что нужно предпринять при работе над продвижением сайта в поиске или создании рекламных объявлений.


Но просто собранные ключевые слова сложно использовать в работе, ведь их необходимо упорядочить. Поэтому после сбора СЯ идет кластеризация запросов – их разделение на группы (кластеры), в соответствии с особенностями и свойствами.
В рамках темы, рассмотрим процесс в действии, а также возможные способы автоматизации. Однако затронем только ключевые аспекты и сервисы, поскольку кластеризация слишком многогранна и для ее описания придется выпустить пару томов.
Часть 1. Подбор семантики
Первичный SEO анализ сайта достаточно показателен, чтобы определиться с общей тематикой ключевых слов. Не придется привлекать каких-то специалистов или обращаться к сервисам, чтобы определиться с тематикой. На этом этапе все просто. Ведь «о чем пишем, те запросы и используем».


Сложности начинаются потом: далеко не всегда понятно, как именно думает пользователь, которому окажется полезен ваш сайт. Если детально разбирать каждый запрос, то можно встретить явление, которое называется «потоком сознания».
Сервисы для кластеризации запросов
Например, человека интересует продвижение сообщества в Facebook. Но искать информацию об этом он может и по запросу «Как продвинуться в мордокниге» (Мордокнига – сленговое название соцсети Facebook). И это тоже придется учесть в работе над семантикой.
Спасает здесь то, что составление семантического ядра для сайта ведется с помощью специализированных сервисов.
- Wordstat – подбор поисковых запросов Яндекса. Частично упрощает кластеризацию, поскольку в выдаче присутствуют все слова из начального запроса с дополнительными формулировками.
- Keyword Planner – практически аналогичный сервис от Google.
- Тренды Google – еще один помощник, который покажет запросы, набирающие популярность.
Некоторые блогеры включают в список Google Correlate, отображающий другие варианты запросов, основанные на поведенческих данных пользователей поисковой системы. Однако в русскоязычном сегменте сети, «отвязанном» от США географически, этот сервис не пригоден, увы.
Но популярность слова «Мордокнига», применительно к Facebook, эти сервисы не отобразят. Поэтому выборку ключей, по которым будет вестись кластеризация запросов, стоит провести и по другим сервисам. Выбор довольно большой:
- Готовые базы. Преимущества – все сделали за вас. Недостатки – не самая высокая достоверность, ведь не учитываются тренды и текущая популярность ключей. Из популярных в .ru зоне – Мутаген, UP Base.
- Специализированные сервисы дадут представление о том, по каким запросам продвигается сайт, причем некоторые покажут СЯ конкурентов. Наиболее популярны SEMRush, Key Collector, Alexa, Ahrefs.
Альтернативные способы сбора семантики
Рассматривать все сервисы для сбора семантики не имеет смысла. Их слишком много, они отличаются механизмами работы, дополнительными параметрами. К тому же, все они разной степени платности. Качественных обзоров в сети достаточно, поэтому подобрать оптимальный по соотношению цены, качества и удобства не составит труда.
Но какой способ сбора семантики предпочесть? Сравним безотносительно конкретных сервисов, а по общим признакам:


- Ручной сбор по подсказкам поисковой системы. Например, Google в последнее время часто показывает похожие запросы в формате «также ищут». Но не обязательно, что удастся почерпнуть какие-то уникальные слова.
- Анализ СЯ конкурентов. Но здесь следует понимать, что найдется далеко не исчерпывающий список, и охват может оказаться не настолько большим, каким он мог быть.
- Специализированные сервисы, например, Serpstat. Система «умеет» работать с похожими фразами, и количество синонимичных запросов довольно большое. Но опять же, кластеризация запросов происходит не всеобъемлюще.
Стоит попробовать все 3 способа, чтобы получить как можно больший охват синонимов и тематически схожих слов. Чем шире охват, тем больший целевой трафик удастся привлечь.
Но при анализе конкурентов нужно обратить внимание на структуру их сайтов, предлагаемый ассортимент и дополнительные услуги. Иначе в необработанную базу запросов попадет «мусор», не соответствующий содержанию сайта, которые будет продвигаться.
Например, предполагается заниматься только продажей садоогородных товаров, из услуг – доставка. У конкурентов расширен товарный ассортимент за счет стройматериалов, малых архитектурных форм. Из дополнительных услуг помимо доставки – ландшафтный дизайн, консультации агронома, вывоз строительного и растительного мусора, спил деревьев и обрезка кустарников. Следовательно, все, что не относится к уже вашему бизнесу – бесполезный мусор, парсить который не имеет смысла.
Так или иначе, но по окончании подбора ключевых слов появляется обширный список, который можно импортировать в формате электронной таблицы для последующей обработки. Кажется, составление семантического ядра завершено. А что делать со всем этим “богатством”?
Сразу приступать к созданию контента? Тогда как определиться, какие ключи будут на каждой из страниц? А что, если итогом работы над СЯ становится 1000+ ключевых слов? Такое количество страниц для небольшого сайта не нужно, да и не все запросы “одинаково полезны”. Некоторые хоть и связаны тематически, но смысла от их использования не будет никакого.
Например, составляется семантика для сайта пасеки. И здесь релевантными окажутся и просто “мед” – информационный запрос и «купить мед» – коммерческий запрос. А вот «лечение подагры медом» уже не имеет отношения к тематике сайта, хотя на первый взгляд кажется, что использовать этот запрос целесообразно.
Вот для распределения запросов и нужна кластеризация ключевых слов. То есть, нужно распределить все слова по «тематическим группам» – кластерам, в соответствии с которыми определить количество страниц и создать уникальный контент для продвижения в поисковых системах или PPC-рекламе.
Часть 2. Кластеризация запросов
Сразу оговорюсь, что не рассматривают кластеризацию в разрезе «soft» и «hard». По большей части для коммерческих сайтов используется именно hard кластеризация. Вариант мягкой классификации используется редко и, по моему мнению, для низкочастотных запросов (то есть тех ключей, по которым конкуренция низкая).
Также хочу оговориться: если сайт состоит из 3-5 страниц, а для продвижения отбирается менее 10 ключей, то особенной потребности в кластеризации СЯ не возникает.
Иное дело, когда отобрано 1000+ запросов. В этом случае нужно выполнить 3 шага
- Сгруппировать ключи по тематике.
- Распределить ключи по группам, в зависимости от их знанчения.
- Оценить совместимость ключевых слов для их использования в пределах 1 страницы сайта
Часть 3. Кластеризатор от SEOquick
Кластеризация запросов от SEOquick позволяет осуществлять морфологический поиск автоматически. Опытные специалисты знают, что это приходится делать вручную, либо при больших финансовых затратах. Вот несколько аргументов в пользу использования инструмента:
- Быстрая работа (если раньше вам требовалось 1 – 2 дня, чтобы создать полноценный список, теперь надо 5 минут).
- Совершенно бесплатный, хотя аналогичные программы стоят дорого (например, за 3000 слов придется отдать 20$).
Шаг 1. Группировка по тематике
Ключевые слова разделяются по группам, в соответствии со структурой сайта. Предположим, что необходимо продвинуть интернет-магазин, посвященный садоводству и продаже семян, удобрений, инвентаря. Условно отделяем коммерческие запросы «купить», «цена», «дешево» от остальных.
Затем распределяются слова по группам – «томаты», «огурцы», «инвентарь», «удобрения». Количество групп определяет первичный SEO анализ сайта, если ресурс уже существует. Если нет или имеются проблемы в структуре, группы дополняются или создаются «с нуля».
Также стоит определиться с геозависимостью и не очевидной коммерцией. Что это? Для примера – единственное и множественное число. Обратимся к поисковикам:
Баклажан для Яндекса – информационный запрос, а баклажанЫ уже коммерческий. То же самое и в Google.
Шаг 2. Оценка совместимости слов на 1 странице по топу выдачи
Далеко не все слова «уживаются» вместе на странице. Но самостоятельно выделить и определить совместимость, особенно если нет опыта, практически невозможно.
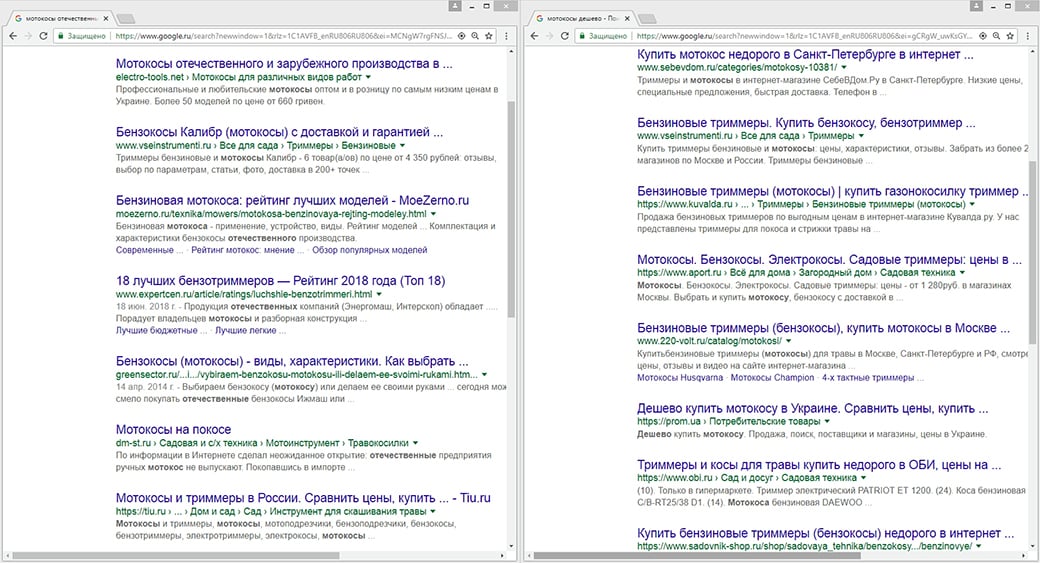
Представим ситуацию, что на 1 и 2 шаге ошибок не совершено и группы собраны с идентичной тематикой. Перейдем к проверке по URL. Для этого вбиваем в поиск фразу «мотокосы купить москва», а затем «мотокосы москва». Совпадает 4 url, следовательно, эти ключи можно использовать на 1 странице.
Продолжим дальше: «мотокосы отечественные» и «мотокосы дешево» не имеют совпадений. Соответственно, стоит разнести эти ключи на разные страницы – вместе они не «уживутся».
Выводы
Закономерна мысль: имея порядка 100 запросов, кластеризовать их вручную по тематике и морфологии еще реально. Но банальная проверка по ТОП/url займет недели, месяцы, годы. Время будет потрачено впустую.
Но с первыми шагами тоже не все просто. Если в таблице будет 1000+ запросов, то только лишь на распределении их по группам и оценке релевантности «сломаются глаза» уже через 8-10 часов непрерывной работы. К тому же, человеческая память «коротка», и возможность пропустить какие-то запросы или создать лишние кластеры тем выше, чем более сложной структурой обладает сайт.
Давайте посчитаем количество страниц для 1 небольшого сайта пасеки:
- Разделы : Главная страница + О компании + Доставка и оплата + Товары + Блог (обзоры/новости/etc.).
- Для раздела Доставка и оплата – 2 страницы (или 1 с большим кластером)
- Товары – количество страниц соответствует ассортименту, но даже если продается всего лишь 5 сортов меда, ульи и пчелы, то количество страниц составит 10-15.
Считаем: В общей сложности более 20 кластеров, для каждого из которых порядка 2 запросов. 20х2=40. Обработка 40 запросов займет не менее дня. Вот только фактический объем, который придется «перелопатить» стоит смело умножать на 10, если семантика собиралась автоматически.
Следовательно, придется автоматизировать этот процесс.
Часть 3. Автоматическая кластеризация запросов
В помощь оптимизатору создано немалое количество сервисов автоматической кластеризации. Их суть – пропуск 1 и 2 шагов и обработка всего массива запросов только по совпадению url. Есть и альтернативные методы разделения. Кластеризация ключевых слов здесь выполняется только по шагу 2.
Хочу заметить: тематическое разделение запросов понадобится только при работе вручную. Во всех остальных случаях алгоритмы кластеризации справятся самостоятельно. Но это не значит, что конечный итог не придется изучать на предмет ошибочного разнесения ключей по подгруппам.
Кластеризация по ТОПу/url
Предполагается, что при таком подходе учитывается алгоритм ранжирования поисковой системы, следовательно, и разделение ключей на группы окажется наиболее точным. Но очевидных минусов здесь предостаточно.
- Алгоритмы ранжирования меняются. Вспомним судьбоносные апдейты у Google – Florida, Panda, Penguin, Pigeon. А ведь ранжирование адаптируется выдачу не под сайты, а под пользователей поисковой системы. А она меняется с течением времени. Спустя 1-2 месяца список сайтов по запросу окажется совсем другим.
- Разные поисковые системы – разные результаты. Сравним выдачу по одинаковому запросу у Google и Яндекс: по запросу «мотокоса» она отличается довольно сильно, нашелся всего пересекающийся 1 url.
- Включение в группу неоднородных слов, которые сложно использовать при создании контента. Представьте вариант, когда в кластер помещается слова «семена герман ф 1» и «корнишоны 6 соток». Да, речь про огурцы, но и ключи разной тематики (1 относится к семенам, 2 – к продукции определенного бренда). Увязать их между собой на карточке товара не то чтобы невозможно, но копирайтеру придется попотеть.
К определенным минусам можно отнести относительную дороговизну сервиса. Однако здесь следует понимать, что инструмент не всегда может быть бесплатным. И каждый сам для себя решает, готов ли он платить и стоит ли услуга своих денег.
Второй, не вполне очевидный недостаток – необходимость доработки семантики. И вдвойне обидно, если кластеризация запросов была платной. Причем сервисы запрашивают немалые суммы, от 150 USD и выше.
Лично мое впечатление от кластеризации методом url/топа выдачи – попытка сделать профессиональный инструмент не вполне разбираясь, как на самом деле работают алгоритмы ранжирования. И вместо реальной работы над контентом и семантикой специалисты пошли по пути наименьшего сопротивления, полагаясь лишь на примитивный перебор вариантов.
Оппоненты же утверждают, что подобный подход – единственно правильный, поскольку гарантирует попадание в ТОП. Сюда же «приплетается» LSi (latent semantic indexing – скрытое семантическое индексирование), поскольку существует «притча» о некой семантической зависимости между словами.
На самом деле, и здесь есть свои нюансы:
- Если на странице встречаются 2 запроса, то это значит, что не Яндекс или Google их признал наиболее релевантными, а что веб-мастер (SEO-специалист) конкретного сайта их туда поместил.
- Семантическая зависимость существует, но в отрыве от ранжирования. К тому же LSi – это больше кластеризация запросов по тематике/морфологии, но не по ТОПу/url
- Выдача адаптирована под конкретного пользователя, тогда как кластеризаторы работают в отрыве от нее. Соответственно у конечного пользователя «картинка» окажется совсем другой, чем у сервисов во время работы над семантикой
Тематическая (семантическая) кластеризация
Альтернативой сервисов разделения ключей по группам на основе ТОП/url являются тематические кластеризаторы.
Здесь правят бал несколько иные принципы, которые можно охарактеризовать следующим образом:
- Анализируется семантическая зависимость каждого из запросов. Не LSi в чистом виде, но что-то близкое. Ведь алгоритму нужно не просто выявить главное слово в запросе, но и подобрать для него пару/аналог, который имеет абсолютно идентичное значение. Например, «томаты – помидоры», «мотокоса – бензиновый триммер». В то же время сервис должен уметь разделять не равные по смыслу, но похожие по написанию ключи. «луковицы тюльпанов – луковицы (в значении лук репчатый)».
- Анализируется состав фразы по словам/сочетанию. Не семантическая (смысловая, синонимичная) зависимость, а именно количество однокоренных слов или целых фраз из них. Например «купить семена герман ф1 – купить герман ф1».
- Анализ геозависимости. Коммерческие запросы геозависимы. Кластеризация ключевых слов обязательно включает в себя фактический источник запроса. Ведь одно дело, когда интернет-магазин работает по Москве, и другое – по Владивостоку. Понятно, что для семантического ядра московского магазина запрос «мотокультиватор владивосток» абсолютно бесполезен, и его не должно быть ни в одной из групп.
Недостатки есть и у этого метода, однако они не такие критические, как в случае с кластеризацией по ТОП/url.
Прежде всего – синонимизация, которую не всегда корректно выполняет алгоритм кластеризатора. Для программного кода фразы «электротриммер – электрокоса», «насос СН90-В – насос СН 90» не всегда имеют знак равенства, поскольку “компьютер” не обладает абстрактным мышлением и потому вполне может разнести их по разным группам.
Второй аспект – внесение в одну группу несовместимых запросов. Например, тип техники: «Погружной грязевой насос – погружной скважинный насос» относятся к разным типам. Еще хуже обстоят дела с моделями техники: «насос SP1 – насос SP3».
Третий аспект – пользователи не всегда полностью указывают местоположение поиска или поисковые системы неправильно определяют регион, соответственно, автоматическая кластеризация запросов не обязательно учтет целевой регион.
Возьмем для примера Костромскую область: Яндекс и Google считают все населенные пункты области за г. Кострому. Однако жителям Шарьи выдача для областного центра не принесет пользы. Расстояние порядка 300 км сделает покупку семян в Костромском интернет-магазине непривлекательной.
Следовательно, результаты работы кластеризатора придется править вручную, даже если сервис предлагает самостоятельно указать неразрывные слова, региональную принадлежность и список синонимов. Но времени на это потратиться все равно меньше, чем, если пытаться все сделать самостоятельно.
Часть 3. Финальная кластеризация запросов
Файл практически готов, из него убран лишний мусор. Осталось пересмотреть кластеры, сосчитать их вес и разнести по категориям.
Шаг 1. Пересмотр кластеров.
Некоторые кластеры после правок обладают, по сути, одинаковым признаком, но разным набором ключей. Следовательно, все их нужно проверить и удалить лишние, то есть те, которые не будут взяты в работу ни сейчас, ни когда-нибудь потом.
Шаг 2. «Вес» кластера
Для каждого ключевого слова установлена частотность. По высокочастотным запросам конкуренция больше, но и прибыль от них выше. SEO-специалисты применяют разные подходы, но чаще всего стараются использовать на странице запросы с разной частотностью – только ВЧ, только СЧ, только НЧ или их сочетания.
На этом шаге можно перегруппировать запросы по кластерам, распределив их в соответствии со своей привычкой. Например, объединить ВЧ-кластеры, или наоборот – разбавить их НЧ или СЧ.
Шаг 3. Подбор страниц
Кластеризация запросов, выполненная для уже существующего сайта, потребует подбора страниц для каждого из созданных кластеров. Можно пойти двумя путями:
- Перераспределить ключи по страницам в соответствии с картой сайта.
- Распределить кластеры с проверкой через поисковик.
В последнем случае в поисковую строку вбивается запрос формата «Ваш сайт» + «Основной Запрос Кластера» (у которого наивысший вес) и берется страница, которая окажется 1 в списке. Но здесь может возникнуть казус: общее содержимое страницы и смысл ключа фактически не релевантны.
Часть 4. Заключительная
Если все сделать правильно, то на выходе получится файл, в котором:
- все ключевые слова собраны по группам (кластерам) и объединены по смыслу;
- для каждого кластера просчитан вес, что определяет очередность работ для копирайтера/контент-менеджера/администратора/программиста;
- подобрана целевая страница или раздел сайта, релевантный запросам.
Рассмотренная кластеризация запросов во многом упрощает продвижение сайта в ТОП. Но нужно понимать, что это – далеко не панацея, и без дополнительных усилий ничего не сработает. Под полученное СЯ необходимо создать уникальный контент (то есть, дать задание копирайтеру и/ или редактору/контент-менеджеру), организовать соответствующую структуру.